Introduction
Speech audiometry is one of the fundamental components of modern hearing diagnostics and audiological clinical research. It has become a basic tool in determining the degree and type of hearing loss, especially in identification of certain retrocochlear pathologies and auditory processing disorders [1-3]. In comparison to pure tone audiometry, which only gives information about absolute perceptual thresholds of tonal sounds, speech audiometry determines speech intelligibility and discrimination between phonemes and provides information about a person's communication abilities in natural listening environments. Speech test results are required to evaluate hearing device fitting, as well as assessment of the outcomes of hearing aid and cochlear implant rehabilitation [4-7].
One of the various measures used in speech audiometry is the speech recognition threshold (SRT). It is defined as “the minimum hearing level for speech at which an individual can recognize 50% of the speech material” [8]. The average SRT is approximately 7-9 dB above the average speech detection threshold, i.e., the lowest sound pressure level (SPL) at which the presence of a speech signal can be heard 50% of the time but can vary between 2 and 16 dB SPL. The SRT is correlated to the puretone hearing threshold average (PTA) of the lower frequency region. Discrepancies between SRT and PTA may occur in patients with auditory disorders, acoustic neuroma or exaggerated hearing loss [9, 10]. SRT is widely used in clinical routine as part of basic audiologic assessment [11, 12] for cross validation of puretone thresholds, measurement of communication disabilities, and as reference for suprathreshold speech audiometry (e.g., at 40 dB sensation level).
Spondaic words are generally recommended for SRT measures in the English language [8]. In German, lists of multisyllabic numerals are used [13-15]. Spondees are used in English [16], Polish [17] and Mandarin [18], while trisyllabic words are used in Japanese [19], Mandarin [20] and Spanish [21, 22]. Also matrix sentence tests are in available for different languages [23-26].
Compared with the rapid development of speech audiometry in Western Countries, the development of speech tests for Armenian speakers dropped behind. In Armenian, valid speech-audiometric materials is currently not available.
The Armenian language is an independent branch of the Indo-European language family. It is the official language of the Republic of Armenia and the Republic of Artsakh. Beside of Armenia with about 3 million inhabitants, Armenian is also widely spoken in the Armenian Diaspora, with about 8-12 million people living throughout the world. The largest communities outside of Armenia are in the Russian Federation, the Islamic Republic of Iran, the French Republic, the United States of America, Canada, the Syrian Arab Republic and the Lebanese Republic.
In order to provide valid and accurate speech intelligibility measurements, speech audiometry needs to be performed in the listener’s native language [27]. Therefore, appropriate audiometric materials are essential. Clinical observations have shown that non-native listeners and patients with diverse linguistic backgrounds typically perform speech tests more poorly than native and/or monolingual hearing-impaired and normal-hearing listeners [28–31]. Consequently, each language should have its own speech materials [32].
Speech material should be developed based on similar, scientifically developed and recognized approaches, but with the regard for characteristics of every language. Simple translation of the developed speech materials from one to another language is inappropriate. This requires speech tests with well-defined properties, such as a careful selection of a sufficiently high number of speech items that are both representative for the underlying language and homogeneous with respect to their intelligibility [22]. Thus, using phonetically or phonemically balanced word lists with the statistically representative distribution of the phoneme incidence in conversional speech is important for the accuracy of the test results [33].
Recognizing the need for linguistically appropriate diagnostic tools, a number of speech tests in different languages (e.g., Russian, Danish, Brazilian Portuguese, Korean, Polish and Japanese among others) have been developed over the past several decades [34, 35, 17, 20]. In German speaking countries, the Freiburg speech intelligibility test [14, 15] is used as part of the standardization (Deutsches Institut für Normung) and as reliable standard for many applications [36, 37].
For speech audiometry, the item lists have to be phonetically balanced and the phoneme distribution should represent the phoneme distribution of the language. For the Armenian language, only a few speech corpuses have been developed. In the 1960s, the Linguistics institute of the Academy of Sciences of the Armenian Soviet Socialist Republic conducted a complete investigation of the peculiarity (acoustic, roentgenological, pronouncing etc.) of Аrmeniаn vowels and consonants, based on which high-, middle- and low-frequency word lists for adults and different age-group children have been developed in Armenian (Hovhannisyan's word lists [38]).
The aim of the current research was to develop, digitally record and evaluate speech-audiometric material that can be used to measure the SRT in quiet in native Armenian speakers.
Material and Methods
Selection and recording of test items
Test material was identified and recorded as reference recording that meets the regulatory normative requirements for speech test material [39]. To create a homogeneous multisyllabic speech corpus, Armenian numerals from 10 to 100 with 2-4 syllables were selected as general sample. Numerals with one, five or six syllables were excluded from the test lists in order to achieve larger uniformity in length of speech items and thus larger homogeneity in auditability.
After phonetic transcription, the phoneme distribution of the general sample was compared to that of the Armenian language. Twenty preliminary test lists were created, presenting each test item in a randomized order. After adjusting for equal phonetic distribution between the lists, 20 phonemically homogeneous test lists (each consisting of 20 numerals or 20 test items) were manually defined. The phonemic structures of the final test lists were compared with the phoneme distribution of the Armenian language [40] by calculation of the Pearson product-moment correlation coefficients.
As reference recording, the items of the final test lists were recorded three times by a trained female native Armenian speaker (Tsovinar Hayrapetyan) with clear pronunciation, a speed of 90-100 syllables/minute, as well as neutral emotion and effort. An U87 high-sensitivity microphone (Neumann, Berlin, Germany) was used in a sound proof chamber of the ''Multimedia Kentron TV'' broadcast studios (Yerevan, Armenia). A sampling rate of 44.100 Hz was used with an A/D rate of 16 bit. MATLAB software (Version 2015, Math Works, Natick, Massachusetts, USA) was used for all calculations and data processing steps. The recorded wave-file was cut and evaluated by the Armenian speaking author (SS) to identify the best recording of each test item regarding naturalness and clarity of speech. After removing time periods without speech, the remaining signal was ramped by a Hanning window with 10 ms of fading in and out times. Silence was added to the end of the signal to generate signals with equalized lengths of 1.5 seconds. After calculation of the root-mean square (RMS) of the signal amplitudes, the level of the individual test items was scaled to the mean RMS of all signals and checked to avoid clipping.
Subjects’ measurements
To measure the speech intelligibility function for every test item, lists containing 10 randomized representations of each test item were presented to the right ear of five otologic normal and normal hearing subjects at a sound pressure level just above (+3 dB), below (-3 dB) and at the individual estimated 50%-speech reception threshold (SRT50) in quiet. The volunteers were recruited among students and patients and signed an informed consent form. The studies has been approved by the institutional ethics committee and has been performed in accordance with the ethical standards as laid down in the 1964 Declaration of Helsinki and its later amendments or comparable ethical standards. All participants were born and raised in Armenia and native Armenian speakers. Before testing, otoscopy and tympanometry was done and completed with normal results. Pure-tone audiometry thresholds were at 10 dB HL or better at frequencies 0.5, 1, 2 and 4 kHz and 15 dB HL or better at 0.25 and 8 kHz, respectively. The test items were presented by an AT900 audiometer (Auritec, Hamburg, Germany) using HDA 300 headphones (Sennheiser, Wennebostel, Germany) in a double-walled soundproof booth fulfilling the requirements of ISO 8253-1 [41]. In order to mimic the normal hearing audiometric test situation, no training of the subjects was provided.
Generation of final test lists
For every test item, speech intelligibility was fitted to a sigmoidal function by logistic regression. The sound pressure levels at the inflection points (SRT50) were calculated for each item and averaged across the subjects. SRT balanced test items were than created by adjusting the RMS level of each item according to the mean SRT50 in limits of +/-3 dB of the SRT averaged across all test items. Normal distribution was testes with the Chi-Square test.
For the final test, twenty lists of twenty SRT balanced items with equal distribution of the numerals were created. The stimulus onset asynchrony of the test was set to 5 s resulting in a total time of 100 s per list.
As calibration signal for the speech material, a noise similar to the CCITT (Comité Consultatif International Téléphonique et Télégraphique) noise that represents distribution of speech energy with a maximum at 800 Hz was created. Therefore, white noise was digitally created and filtered according to limits of 20 and 8.000 Hz. The RMS level was adjusted to the mean RMS level of all test items according to the normative restrictions [41]. The test items and the calibration signal were stored as single-channel signals to an audio compact disc to be used with standard clinical audiometers.
Results
Figure 1 shows the distribution of syllables in the corpus of Armenian numerals from 10 to 100. Monosyllabic and six syllabic words occurred with a percentage of 2.2% each, 14.3% of the numerals were two syllabic, 36.3% three syllabic, 30.7% four syllabic, and 14.3% five-syllabic ones. All of the two- to four-syllabic numerals were selected and included to create the test lists.

Figure 1. Syllabic structure of Armenian numerals from 10 to 100 (percentage of occurrence of mono- by, tri-, four- five- and six syllabic numerals among the all 10 to 100 Armenian numerals).
The phoneme distribution of the selected numerals (general sample) according to symbols of the IPA phoneme alphabet [42] is shown in Figure 2. The most frequent phonemes are the consonants [n/ŋ] and [s] with frequencies of 16.6% and 12.8%, respectively. The most frequent vowels are [u] (12.3%), followed by [ɛ] and [ɑ] (7.4% each). The frequency of the other phonemes varies from 5.7% to 2.0%. The most rare phonemes are the consonants [m], [t͡sʰ], [t͡ʃʰ], [g] and [r] with frequencies of 1.3%. Based on this phonemic structure, 20 phonemically homogeneous test lists with 20 numerals in each were created (Table 1). The phoneme distributions of those test lists are also shown in Figure 2. The phoneme distributions of each test list correlated significantly and positively with that of the general sample (all Pearson moment correlation coefficients > 0.960; all ps 0.001).
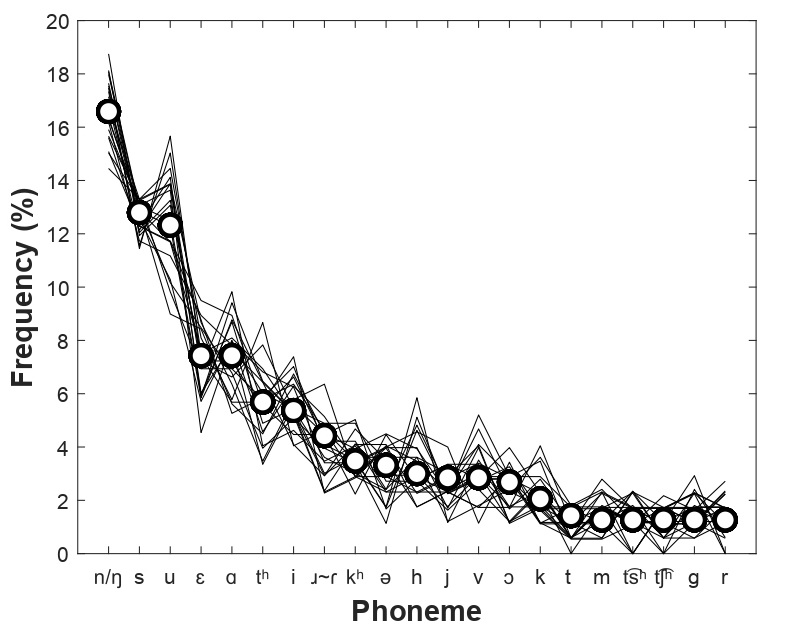
Figure 2. Phoneme distributions of the general sample (open circles) and of the 20 test lists (thin lines).
Table 1. Structure of Armenian Multisyllabic Numbers Test: 20 test lists with 20 numerals in each
|
Test lists |
|||||||||||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
Test items (numerals) |
|||||||||||||||||||
|
52 |
66 |
15 |
66 |
39 |
47 |
40 |
29 |
68 |
50 |
18 |
37 |
62 |
49 |
59 |
57 |
16 |
69 |
51 |
95 |
|
54 |
81 |
60 |
29 |
55 |
68 |
67 |
90 |
61 |
37 |
64 |
94 |
53 |
45 |
34 |
94 |
41 |
58 |
69 |
69 |
|
58 |
67 |
68 |
98 |
88 |
34 |
48 |
86 |
55 |
90 |
21 |
97 |
15 |
84 |
40 |
41 |
96 |
44 |
27 |
34 |
|
14 |
37 |
21 |
30 |
52 |
23 |
25 |
70 |
100 |
24 |
51 |
23 |
54 |
94 |
36 |
53 |
46 |
86 |
46 |
50 |
|
15 |
23 |
70 |
95 |
40 |
87 |
41 |
66 |
86 |
58 |
85 |
99 |
82 |
55 |
49 |
23 |
99 |
23 |
91 |
61 |
|
80 |
21 |
29 |
96 |
24 |
56 |
61 |
38 |
95 |
61 |
45 |
16 |
90 |
86 |
64 |
45 |
24 |
81 |
84 |
65 |
|
48 |
45 |
53 |
61 |
45 |
88 |
56 |
85 |
27 |
45 |
31 |
21 |
49 |
23 |
11 |
69 |
65 |
36 |
36 |
56 |
|
21 |
11 |
61 |
46 |
82 |
45 |
65 |
91 |
31 |
91 |
61 |
55 |
22 |
29 |
51 |
81 |
91 |
65 |
55 |
18 |
|
82 |
54 |
46 |
14 |
31 |
61 |
69 |
22 |
53 |
35 |
70 |
11 |
14 |
98 |
47 |
65 |
18 |
68 |
61 |
17 |
|
85 |
26 |
88 |
16 |
57 |
41 |
99 |
25 |
40 |
65 |
90 |
25 |
81 |
12 |
68 |
67 |
50 |
85 |
96 |
85 |
|
17 |
91 |
54 |
67 |
51 |
53 |
91 |
81 |
18 |
47 |
12 |
24 |
100 |
34 |
65 |
80 |
86 |
83 |
83 |
51 |
|
61 |
94 |
47 |
27 |
84 |
35 |
46 |
83 |
46 |
14 |
34 |
66 |
52 |
61 |
31 |
84 |
53 |
84 |
16 |
63 |
|
86 |
99 |
90 |
82 |
63 |
28 |
38 |
18 |
89 |
99 |
15 |
15 |
31 |
53 |
91 |
47 |
62 |
16 |
89 |
55 |
|
26 |
96 |
55 |
84 |
41 |
96 |
36 |
51 |
38 |
28 |
26 |
68 |
56 |
82 |
95 |
52 |
28 |
34 |
85 |
24 |
|
49 |
65 |
48 |
85 |
27 |
19 |
37 |
100 |
29 |
44 |
29 |
35 |
46 |
97 |
30 |
64 |
98 |
62 |
68 |
81 |
|
51 |
34 |
40 |
87 |
19 |
54 |
58 |
65 |
25 |
17 |
44 |
51 |
97 |
44 |
41 |
60 |
29 |
57 |
25 |
13 |
|
81 |
15 |
91 |
40 |
61 |
46 |
88 |
49 |
58 |
38 |
58 |
83 |
40 |
60 |
100 |
70 |
63 |
97 |
35 |
83 |
|
23 |
38 |
82 |
28 |
58 |
70 |
12 |
87 |
94 |
100 |
27 |
84 |
38 |
47 |
16 |
85 |
37 |
26 |
58 |
53 |
|
70 |
40 |
96 |
23 |
54 |
13 |
98 |
88 |
22 |
15 |
96 |
59 |
91 |
65 |
99 |
51 |
67 |
60 |
40 |
25 |
|
99 |
80 |
38 |
45 |
69 |
39 |
80 |
35 |
56 |
53 |
46 |
63 |
89 |
46 |
86 |
55 |
87 |
89 |
99 |
86 |
Figure 3 shows the phoneme distributions of the test lists and general sample in comparison to that of the Armenian language corpus mean [40]. Both phoneme distributions correlated significantly and positively (Pearson moment correlation coefficient = 0.998, p<0.001). From the 36 phonemes of the Armenian language, only 21 are represented in the general sample and subsequently in the test lists. Comparing the test lists and the Armenian language, the largest phoneme distribution differences were found in the phonemes [s], [n/ŋ] and [u], which are 9.1%, 8% and 7.6% respectively more frequently represented in the test lists; and phoneme [ɑ], which is represented 7.2% less. The frequencies of the other phonemes varied 0-4% between both distributions.

Figure 3. Phonemic structure of general sample (dotted line), test lists (solid line with open circles) and corpus (solid line with black circles).
Figure 4 shows the SRT50 and the slope of the speech discrimination function for all test items as average across the subjects. The mean SRT50 across the subjects and test items was 20.8 dB SPL (SD=2.69 dB). The mean slope of the speech discrimination function was 17.9 %/dB (SD=6.8 %/dB). Both, the distributions of SRT50 and the slopes were not different from a normal distribution (c2(55)=15.35, p=1). The resulting correction values for the final RMS scaling of the balanced test items were derived from the difference of the item specific SRT50 to the global mean SRT50 and limited to ±3 dB. Figure 5 shows the frequency spectrum of the calibration noise signal.
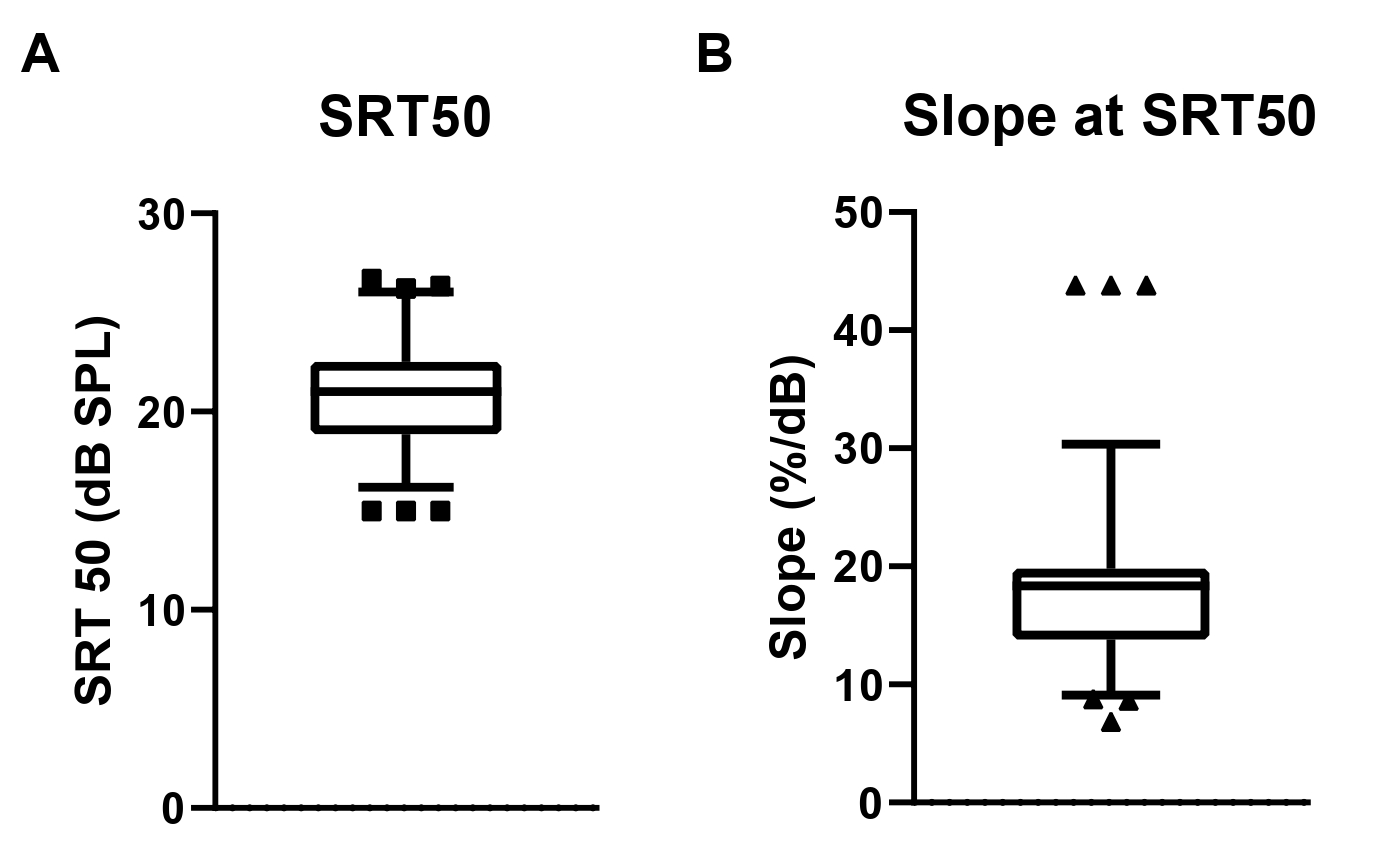
Figure 4. Distributions of A. SRT50 and B. the slopes at the SRT50 for all test items averaged across the subjects. Box plots show the median, 25 and 75 percentiles. Whiskers mark the the 5 and 95 percentiles.
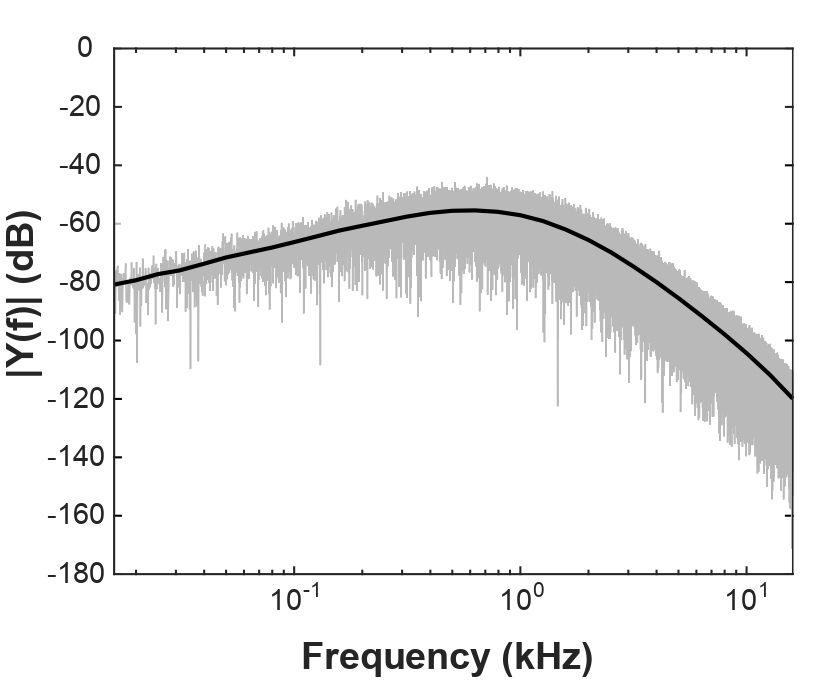
Figure 5. Frequency spectrum of the CCITT noise for calibration.
Discussion
The aim of this study was to develop, record and evaluate speech materials in line with internationally accepted criteria for SRT measurements in native Armenian speakers. Twenty lists of numerals based on the phonemic structure of Armenian numerals were developed based on a general sample. The results show equivalence between phonemic distributions of the test lists and the general sample. Therefore, the resulting test material is a phonemically homogeneous and representative sample of spoken Armenian language [40].
To form the so-called Khachatryan corpus, 10.000 character passages have been selected from literary, scientific, physics and math texts. No significant phoneme distribution differences between the text types were found for the vowels: the most frequent one is always [ɑ], followed by [ɛ]. Only the vowels [u] and [ə] have swapped ranks between the text types. Variations among consonants are larger, however, the sonants [n/ŋ], [m], and [ɹ~ɾ] are among the most repeated phonemes and represent the first six ranks in the phoneme distribution table, followed by the consonants [s], [k] and [v], which ranks differ from each other by one or two places. The least frequent phoneme is [f], when it comes to the literary text, but it is more frequently encountered in mathematical texts.
Since not all the phonemes of the Armenian language are represented in the numerals and thus in the selected test items, the comparison of the phoneme distribution of the test lists with that of the Armenian language showed deviations. However, the comparison between the phoneme distributions (Figure 3) shows that the test lists represent the language corpus quite well.
The developed test is intended to measure the threshold of speech intelligibility, but not vocabulary or intelligence [43]. Test material for developing speech audiometric tests should meet the requirements of familiarity, phonetic dissimilarity, representative sample of speech sounds, and homogeneity with respect to audibility [43]. For SRT measurements, however, only familiarity and homogeneity of audibility were identified as most important [27]. The use of numerals is based on previous research and clinical reports showing the applicability of using digit stimuli for SRT measurements [44]. Digits are also preferred because of the highest familiarity and are homogeneity with respect to audibility [45]. Both requirements are also fulfilled by the present test material.
The results show a mean SRT of 20.8 dB SPL for the Armenian test items. This is in line with SRT measurements of other languages using numerals as test items [37]. Further, numerals demonstrate the steepest articulation function among speech audiometric stimuli [45]. The present results show a mean slope of 17.9 %/dB at the inflection point of the speech intelligibility functions (i.e., the SRT level), which is almost equal to that of the Oldenburg matrix test for test lists of German sentences [26].
Twenty test lists were selected to avoid redundancy if patients were tested repeatedly. The RMS level of the test items was balanced across all test items to assume equal SRT values across the test lists. The next steps will be the comparison of the speech intelligibility functions across the test lists in a larger cohort of normal hearing and hearing impaired native Armenian speaking subjects.
Conclusion
In conclusion, the developed test lists are a phonetically homogenous representation of the Armenian language and provide an appropriated base to clinically measure SRT in Armenian speaking listeners.
Acknowledgments
The authors thank Tsovinar Hayrapetyan for recording the test items and the National Broadcast Studios (Yerevan, Armenia) for providing the technical infrastructure for the recording.
Conflict of interest
The authors declare no conflicts of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
- American Speech-Language-Hearing Association Central Auditory Processing Disorder. Rockville, MD: American Speech-Language-Hearing Association. 2021. https://www.asha.org/practice-portal/clinical-topics/central-auditory-processing-disorder/
- Campbell NG, Alles R, Bamiou D, Batchelor L, Canning D, Grant P, et al. BSA Practice Guidance: An overview of current management of auditory processing disorder (APD). Berkshire: British Society of Audiology. 2011; 60 p. http://eprints.soton.ac.uk/id/eprint/338016.
- Katz J, Chasin M, English KM, Hood LJ, Tillery KL, eds. Handbook of clinical audiology. Philadelphia: Wolters Kluwer Health. 2015; 927 p. https://www.worldcat.org/title/handbook-of-clinical-audiology/oclc/877024342.
- Evans PIP. Speech audiometry for differential diagnosis. In: Martin M, ed. Speech audiometry. London: Taylor & Francis. 1987: 109-125.
- Humes LE. Modeling and Predicting Hearing Aid Outcome. Trends Amplif 2003; 7(2): 41-75. https://doi.org/10.1177/108471380300700202.
- Humes LE, Wilson DL. An Examination of Changes in Hearing-Aid Performance and Benefit in the Elderly Over a 3-Year Period of Hearing-Aid Use. J Speech Lang Hear Res 2003; 46(1): 137-145. https://doi.org/10.1044/1092-4388(2003/011).
- Parving A. The Value of Speech Audiometry in Hearing-Aid Rehabilitation. Scand Audiol 1991; 20(3): 159-164. https://doi.org/10.3109/01050399109074948.
- Guidelines for determining threshold level for speech. ASHA 1988; 30(3): 85-89. https://pubmed.ncbi.nlm.nih.gov/3155355/.
- Van Dijk JE, Duijndam J, Graamans K. Acoustic Neuroma: Deterioration of Speech Discrimination Related to Thresholds in Pure-Tone Audiometry. Acta Otolaryngol 2000; 120(5): 627-632. https://doi.org/10.1080/000164800750000450.
- Wilson RH, Margolis RH. Measurements of auditory thresholds for speech stimuli. In: Konkle DF, Rintelmann WF, eds. Principles of speech audiometry. Baltimore: University Park Press. 1983; 79-126. https://www.worldcat.org/title/principles-of-speech-audiometry/oclc/8688317.
- American Speech-Language-Hearing Association. Audiology Survey. Rockville, MD. 2016. 18 p. https://www.asha.org/siteassets/surveys/2016-audiology-survey-private-practice.pdf.
- Martin FN, Champlin CA, Chambers JA. Seventh survey of audiometric practices in the United States. J Am Acad Audiol 1998; 9(2): 95-104. https://pubmed.ncbi.nlm.nih.gov/9564671/.
- Word lists for recognition tests – Part 1: Monosyllabic and polysyllabic words. DIN 45621-1:1995-08. Berlin: Beuth Verlag GmbH. 1995; 2 p. German. https://www.beuth.de/de/norm/din-45621-1/2573874.
- Hahlbrock KH. Speech audiometry and new word-tests. Arch Ohren Nasen Kehlkopfheilkd. 1953; 162(5): 394-431. https://doi.org/10.1007/BF02105664.
- Hahlbrock KH. Sprachaudiometrie: Grundlagen und Praktische Anwendung Einer Sprachaudiometrie für Das Deutsche Sprachgebiet (German Edition). 2nd ed. Stuttgart, Germany: Georg Thieme. 1970. German.
- Egan JP. Articulation testing methods. Laryngoscope 1948; 58(9): 955-991. https://doi.org/10.1288/00005537-194809000-00002.
- Harris RW, Nielson WS, McPherson DL, Skarzynski H, Eggett DL. Psychometrically equivalent Polish bisyllabic words spoken by male and female talkers. Audiofonologia 2004; 25: 1-15.
- Nissen SL, Harris RW, Jennings LJ, Eggett DL, Buck H. Psychometrically equivalent trisyllabic words for speech reception threshold testing in Mandarin. Int J Audiol 2005; 44(7): 391-399. https://doi.org/10.1080/14992020500147672.
- Shport IA. Perception of acoustic cues to Tokyo Japanese pitch-accent contrasts in native Japanese and naive English listeners. J Acoust Soc Am 2015; 138(1): 307-318. https://doi.org/10.1121/1.4922468.
- Nissen SL, Harris RW, Jennings LJ, Eggett DL, Buck H. Psychometrically equivalent mandarin bisyllabic speech discrimination materials spoken by male and female talkers. Int J Audiol 2005; 44(7): 379-390. https://doi.org/10.1080/14992020500147615.
- Carlo MA, Wilson RH, Villanueva-Reyes A. Psychometric Characteristics of Spanish Monosyllabic, Bisyllabic, and Trisyllabic Words for Use in Word-Recognition Protocols. J Am Acad Audiol 2020; 31(7): 531-546. https://doi.org/10.1055/s-0040-1709446.
- Warzybok A, Zokoll M, Wardenga N, Ozimek E, Boboshko M, Kollmeier B. Development of the Russian matrix sentence test. Int J Audiol 2015; 54(sup2): 35-43. https://doi.org/10.3109/14992027.2015.1020969.
- Mungan Durankaya S, Serbetcioglu B, Dalkilic G, Gurkan S, Kirkim G. Development of a Turkish Monosyllabic Word Recognition Test for Adults. Int Adv Otol 2014; 10(2): 172-180. https://doi.org/10.5152/iao.2014.118.
- Wagener K, Kühnel V, Kollmeier B. Entwicklung und Evaluation eines Satztests für die deutsche Sprache I: Design des Oldenburger Satztests. Z Audiol 1999; 38: 4-15. German.
- Wagener K, Kühnel V, Kollmeier B. Entwicklung und Evaluation eines Satztests für die deutsche Sprache II: Optimierung des Oldenburger Satztests. Z Audiol 1999; 38: 44-56. German.
- Wagener K, Kühnel V, Kollmeier B. Entwicklung und Evaluation eines Satztests für die deutsche Sprache III: Evaluation des Oldenburger Satztests. Z Audiol 1999; 38: 86-95. German.
- Ramkissoon I. Speech Recognition Thresholds for Multilingual Populations. Commun Disord Q 2001; 22(3): 158-162. https://doi.org/10.1177/152574010102200305.
- Marinova-Todd SH, Siu CK, Jenstad LM. Speech audiometry with non-native English speakers: The use of digits and Cantonese words as stimuli. Can J Speech Lang Pathol Audiol 2011; 35(3): 220-227.
- Ramkissoon I, Khan F. Serving Multilingual Clients With Hearing Loss. ASHA Lead 2003; 8(3): 1-27. https://doi.org/10.1044/leader.FTR1.08032003.1.
- Takayanagi S, Dirks DD, Moshfegh A. Lexical and Talker Effects on Word Recognition Among Native and Non-Native Listeners With Normal and Impaired Hearing. J Speech Lang Hear Res 2002; 45(3): 585-597. https://doi.org/10.1044/1092-4388(2002/047).
- Warzybok A, Brand T, Wagener KC, Kollmeier B. How much does language proficiency by non-native listeners influence speech audiometric tests in noise. Int J Audiol 2015; 54(sup2): 88-99. https://doi.org/10.3109/14992027.2015.1063715.
- Vaucher AVA, Menegotto IH, Moraes AB, Costa MJ. Listas de monossílabos para teste logoaudiométrico: validação de construto. Audiol Commun Res 2017; 22: e1729. English, Portuguese. https://doi.org/10.1590/2317-6431-2016-1729.
- Exter M, Winkler A, Holube I. Phonemische Ausgewogenheit des Freiburger Einsilbertests. HNO 2016; 64(8): 557-563. German. https://doi.org/10.1007/s00106-016-0185-z.
- Aleksandrovsky IV, McCullough JK, Wilson RH. Development of suprathreshold word recognition test for Russian-speaking patients. J Am Acad Audiol 1998; 9(6): 417-425. https://pubmed.ncbi.nlm.nih.gov/9865774.
- Elberling C, Ludvigsen C, Lyregaard PE. DANTALE: A New Danish Speech Material. Scand Audiol 1989; 18(3): 169-175. https://doi.org/10.3109/01050398909070742.
- Baljić I, Hoppe U. The Freiburg monosyllabic test put to the test. HNO 2016; 64(8): 538-539. German. https://doi.org/10.1007/s00106-016-0208-9.
- Hoth S. The Freiburg speech intelligibility test: A pillar of speech audiometry in German-speaking countries. HNO 2016; 64(8): 540-548. German. https://doi.org/10.1007/s00106-016-0150-x.
- Hovhannisyan JM. The checking of the auditory acuity by the method of speech audiometry using the word tables in Armenian language. Biol Z Armen 1970; 23: 76-83. http://biology.asj-oa.am/5038.
- ISO 8253-3:2012(en). Acoustics — Audiometric test methods — Part 3: Speech audiometry. 2012. https://www.iso.org/obp/ui/#iso:std:iso:8253:-3:ed-2:v1:en.
- Khachatryan AH, Tokhmakhyan RM. Modern Armenian phonology. Yerevan, Armenia. 1988.
- ISO 8253-1:2010(en). Acoustics — Audiometric test methods — Part 1: Pure-tone air and bone conduction audiometry. 2010; 29 p. https://www.iso.org/obp/ui/#iso:std:iso:8253:-1:ed-2:v1:en.
- International Phonetic Association. Handbook of the International Phonetic Association. A guide to the use of the international phonetic alphabet. Cambridge: Cambridge University Press. 1999; 204 p. https://www.cambridge.org/core/journals/phonology/article/abs/handbook-of-the-international-phonetic-association-a-guide-to-the-use-of-the-international-phonetic-alphabet-1999-cambridge-cambridge-university-press-pp-ix204/34A67CCB6880AF5D185CFA1726DEEB33.
- Hudgins CV, Hawkins JE. The development of recorded auditory tests for measuring hearing loss for speech. Laryngoscope 1947; 57(1): 57-89. https://pubmed.ncbi.nlm.nih.gov/20287775.
- Ramkissoon I, Proctor A, Lansing CR, Bilger RC. Digit Speech Recognition Thresholds (SRT) for Non-Native Speakers of English. Am J Audiol 2002; 11(1): 23-28. https://doi.org/10.1044/1059-0889(2002/005).
- Miller GA, Heise GA, Lichten W. The intelligibility of speech as a function of the context of the test materials. J Exp Psychol 1951; 41(5): 329-335. https://doi.org/10.1037/h0062491.
Received 25 January 2021, Revised 22 April 2021, Accepted 27 April 2021
© 2021, Russian Open Medical Journal
Correspondence to Torsten Rahne. Address: University Hospital Halle (Saale), Department of Otorhinolaryngology, Head & Neck Surgery, Ernst-Grube-Straße 40, 06120 Halle (Saale), Germany. Email: torsten.rahne@uk-halle.de.